hadoop 集群HA高可用搭建
目录大纲
1. hadoop HA原理
2. hadoop HA特点
3. Zookeeper 配置
4. 安装Hadoop集群
5. Hadoop HA配置
搭建环境
| 环境 |
版本 |
地址地址 |
| CentOS |
6.5 64x |
点击下载 |
| hadoop |
2.5.1 |
点击下载 |
| Zookeeper |
3.4.5 |
点击下载 |
| Hadoop Ha配置 |
null |
点击下载 |
| null |
null |
null |
| ch01 |
192.168.128.121 |
NN DN RM |
| ch02 |
192.168.128.122 |
NN DN NM |
| ch03 |
192.168.128.123 |
DN NM |
Hadoop HA原理

在一个典型的HA集群中,每个NameNode是一台独立的服务器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。

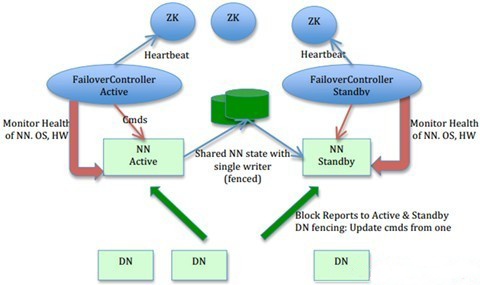
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了,如图3所示。
Hadoop Ha特点
Zookeeper 配置
1)配置zoo.cfg(默认是没有zoo.cfg,将zoo_sample.cfg复制一份,并命名为zoo.cfg)
[root@ch01 conf]# vi /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# the port at which the clients will connect
clientPort=2181
dataDir=/opt/hadoop/zookeeper-3.4.5-cdh5.6.0/data
dataLogDir=/opt/hadoop/zookeeper-3.4.5-cdh5.6.0/logs
server.1=ch01:2888:3888
server.2=ch02:2888:3888
server.3=ch03:2888:3888
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
2)将zookeeper从ch01复制到ch02,ch03机器上
scp -r /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/ root@ch02:/opt/hadoop/
scp -r /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/ root@ch03:/opt/hadoop/
3)在ch01 02 c03中创建/opt/Hadoop/zookeeper-3.4.5-cdh5.6.0/data目录下创建myid文件,内容为zoo.cfg中server.x所配置的数字
ch01=1
ch02=2
ch03=3
命令:
[root@ch01 ~]# mkdir /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/data //创建目录
[root@ch01 ~]# echo 1 > /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/data/myid //使用脚本命令 echo 写入
[root@ch01 ~]# ssh ch02 //登录ch02机器
Last login: Mon Feb 20 03:15:04 2017 from 192.168.128.1
[root@ch02 ~]# mkdir /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/data //创建目录
[root@ch02 ~]# echo 2 > /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/data/myid //使用脚本命令 echo 写入
[root@ch02 ~]# exit //退出ch02机器节点
logout
Connection to ch02 closed.
[root@ch01 ~]# ssh ch03 //登录ch02机器
Last login: Sun Feb 19 16:13:53 2017 from 192.168.128.1
[root@ch03 ~]# mkdir /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/data //创建目录
[root@ch03 ~]# echo 3 > /opt/hadoop/zookeeper-3.4.5-cdh5.6.0/data/myid //使用脚本命令 echo 写入
[root@ch03 ~]# exit //退出ch02机器节点
安装Hadoop集群
需要修改的文件配置
1. core-site.xml
2. hadoop-env.sh
2. hdfs-site.xml
3. mapred-site.xml
4. yarn-site.xml
5. slaves
core-site.xml
<configuration>
<property>
<!-- 配置 hadoop NameNode ip地址 ,由于我们配置的 HA 那么有两个namenode 所以这里配置的地址必须是动态的-->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 整合 Zookeeper -->
<name>ha.zookeeper.quorum</name>
<value>ch01:2181,ch02:2181,ch03:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/hadoop-2.6.0-cdh5.6.0/tmp/</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--命名空间设置ns1-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--namenodes节点ID:nn1,nn2(配置在命名空间mycluster下)-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1,nn2节点地址配置-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>ch01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>ch02:8020</value>
</property>
<!--nn1,nn2节点WEB地址配置-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>ch01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>ch02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ch01:8485;ch02:8485;ch03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>file:/opt/hadoop/hadoop-2.6.0-cdh5.6.0/tmp/dfs/journalnode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hadoop-2.6.0-cdh5.6.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/opt/hadoop/hadoop-2.6.0-cdh5.6.0/tmp/dfs/data</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--启用自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.replication.max</name>
<value>32767</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framwork.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ch01</value>
</property>
</configuration>
slaves
ch01
ch02
ch03
使用Zookeeper
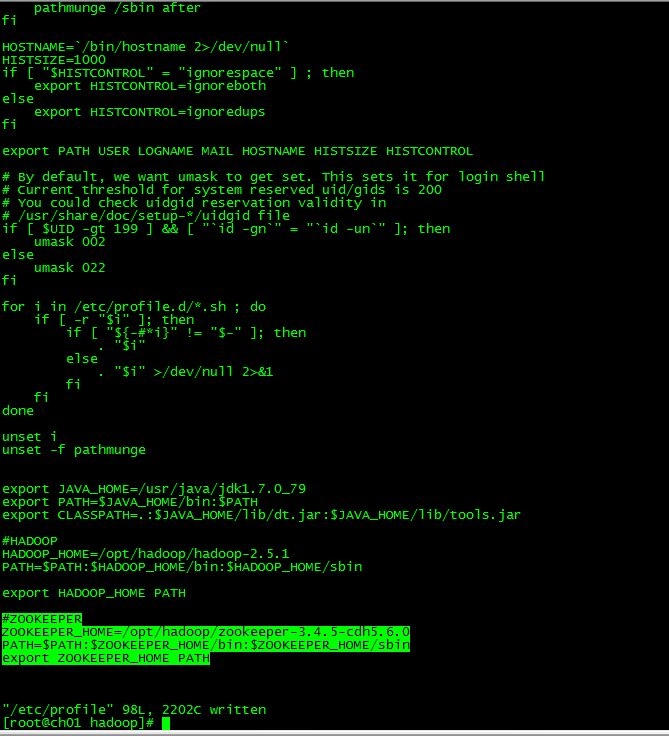
配置Zookeeper环境变量
[root@ch01 ~]#vi /etc/profile
#ZOOKEEPER
ZOOKEEPER_HOME=/opt/hadoop/zookeeper-3.4.5-cdh5.6.0 //安装目录
PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/sbin
export ZOOKEEPER_HOME PATH
启动Zookeeper
1)在ch01,ch02,ch03所有机器上执行,下面的代码是在ch01上执行的示例:
root@ch01:zkServer.sh start
JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
root@ch01:/home/hadoop# /opt/hadoop/zookeeper-3.4.5/bin/zkServer.sh status
JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
2)在每台机器上执行下面的命令,可以查看状态,在ch01上是leader,其他机器是follower
3)测试zookeeper是否启动成功,看下面第29行高亮处,表示成功。
zkCli.sh
4)在ch01上格式化zookeeper,第33行的日志表示创建成功。
hdfs zkfc -formatZK
5)验证zkfc是否格式化成功,如果多了一个hadoop-ha包就是成功了。
zkCli.sh
启动JournalNode集群
1)依次在ch01,ch02,ch03上面执行
hadoop-daemon.sh start journalnode
2)格式化集群的一个NameNode(ch01),有两种方法,我使用的是第一种
hdfs namenode –format
3)在ch01上启动刚才格式化的 namenode
hadoop-daemon.sh start namenode
4)在ch01机器上,将ch01的数据复制到ch02上来,在ch02上执行
hdfs namenode –bootstrapStandby
5)启动ch02上的namenode,执行命令后
hadoop-daemon.sh start namenode
浏览:http://ch02:50070/dfshealth.jsp可以看到m2的状态。
这个时候在网址上可以发现m1和m2的状态都是standby。
6)启动所有的datanode,在ch01上执行
hadoop-daemons.sh start datanode
7)启动yarn,在ch01上执行以下命令
start-yarn.sh
8)、启动 ZooKeeperFailoverCotroller,在ch01,ch02机器上依次执行以下命令,这个时候再浏览50070端口,可以发现ch01变成active状态了,而m2还是standby状态
hadoop-daemon.sh start zkfc
10)、测试HDFS是否可用
/home/hadoop/hadoop-2.2.0/bin/hdfs dfs -ls /
问题
journalnode启动失败
[root@ch01 hadoop]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/hadoop/hadoop-2.6.0-cdh5.6.0/logs/hadoop-root-journalnode-ch01.out
Exception in thread "main" java.lang.IllegalArgumentException: Journal dir 'file:/opt/hadoop/hadoop-2.6.0-cdh5.6.0/tmp/dfs/journalnode' should be an absolute path
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.validateAndCreateJournalDir(JournalNode.java:120)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.start(JournalNode.java:144)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.run(JournalNode.java:134)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.main(JournalNode.java:307)
解决:将HDFS-site.xml中的journalnode属性value的值设置为绝对路径.不需要加file:关键字
DataNode启动失败
Java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:477)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1394)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1355)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:228)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:829)
at java.lang.Thread.run(Thread.java:745)
2017-02-20 10:25:39,363 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool (Datanode Uuid unassigned) service to ch02/192.168.128.122:8020. Exiting.
java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:477)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1394)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1355)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:228)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:829)
at java.lang.Thread.run(Thread.java:745)
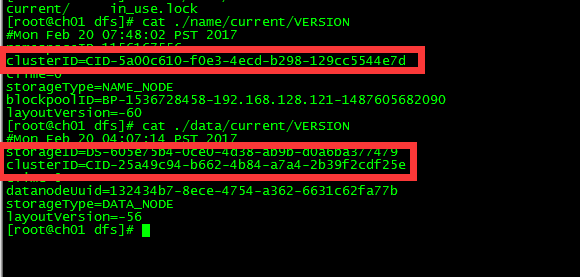
解决:原因是因为,Namenode中的namenode CID-5a00c610-f0e3-4ecd-b298-129cc5544e7d和DataNode中的CID不一致导致的
梦柯教育 | 
 |手机版|小黑屋|Java自学者论坛
( 声明:本站文章及资料整理自互联网,用于Java自学者交流学习使用,对资料版权不负任何法律责任,若有侵权请及时联系客服屏蔽删除 )
|手机版|小黑屋|Java自学者论坛
( 声明:本站文章及资料整理自互联网,用于Java自学者交流学习使用,对资料版权不负任何法律责任,若有侵权请及时联系客服屏蔽删除 )




 发表于 2021-8-31 10:39:40
发表于 2021-8-31 10:39:40