引言
今天针对线上生产环境下单机 flume 拉取kafka数据并存储数据入Hdfs 出现大批量数据延迟. 在网上官网各种搜索数据,并结合官网数据,现进行以下总结
1. 线上单机存在问题简述
当前flume拉取kafa数据量并不大 ,根据flume客户端日志 ,每半分钟hdfs文件写入一次数据生成文件
发现问题:
拉取kafka数据过慢
2. 解决思路
- 加大kafka拉取数据量
- 加大flume中channel,source,sink 各通道的单条数据量
- 将flume拉取数据单机版本改成多数据拉取,通过flume-avore-sink-> flume-avore-source 进行数据多数据采取并合并
3 加大kafka拉取数据量
3.1 kafka-source简述
- flume 输入单线程拉取数据并将数据发送内置channel并通过sink组件进行数据转发和处理,故对于kafka集群多副本方式拉取数据的时候,应适当考虑多个flume节点拉取kafka多副本数据,以避免flume节点在多个kafka集群副本中轮询。加大flume拉取kafka数据的速率。
- flume-kafka-source 是flume内置的kafka source数据组件,是为了拉取kafka数据,配置如下:
agent.sources = r1
agent.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.r1.batchSize = 50000
agent.sources.r1.batchDurationMillis = 2000
agent.sources.r1.kafka.bootstrap.servers = test-hadoop01:9092
agent.sources.r1.kafka.topics = topicTest
agent.sources.r1.kafka.consumer.group.id = groupTest
- flume-kafka-source 的offset是交由zk集群去维护offset
3.2 kafka-source配置详解
Kafka Source是一个Apache Kafka消费者,它从Kafka主题中读取消息。 如果您正在运行多个Kafka源,则可以使用相同的使用者组配置它们,以便每个源都读取一组唯一的主题分区。
| Property Name |
Default |
Description |
| channels |
– |
配置的channels 可配置多个channels 后续文章会说到 |
| type |
– |
org.apache.flume.source.kafka.KafkaSource |
| kafka.bootstrap.servers |
– |
配置kafka集群地址 |
| kafka.consumer.group.id |
flume |
唯一确定的消费者群体。 在多个源或代理中设置相同的ID表示它们是同一个使用者组的一部分 |
| kafka.topics |
– |
你需要消费的topic |
| kafka.topics.regex |
– |
正则表达式,用于定义源订阅的主题集。 此属性的优先级高于kafka.topics,如果存在则覆盖kafka.topics。 |
| batchSize |
1000 |
一批中写入Channel的最大消息数 (优化项) |
| batchDurationMillis |
1000 |
将批次写入通道之前的最长时间(以毫秒为单位)只要达到第一个大小和时间,就会写入批次。(优化项) |
| backoffSleepIncrement |
1000 |
Kafka主题显示为空时触发的初始和增量等待时间。 等待时间将减少对空kafka主题的激进ping操作。 一秒钟是摄取用例的理想选择,但使用拦截器的低延迟操作可能需要较低的值。 |
| maxBackoffSleep |
5000 |
Kafka主题显示为空时触发的最长等待时间。 5秒是摄取用例的理想选择,但使用拦截器的低延迟操作可能需要较低的值。 |
| useFlumeEventFormat |
false |
默认情况下,事件从Kafka主题直接作为字节直接进入事件主体。 设置为true以将事件读取为Flume Avro二进制格式。 与KafkaSink上的相同属性或Kafka Channel上的parseAsFlumeEvent属性一起使用时,这将保留在生成端发送的任何Flume标头。 |
| setTopicHeader |
true |
设置为true时,将检索到的消息的主题存储到标题中,该标题由topicHeader属性定义。 |
| topicHeader |
topic |
如果setTopicHeader属性设置为true,则定义用于存储接收消息主题名称的标题的名称。 如果与Kafka SinktopicHeader属性结合使用,应该小心,以避免在循环中将消息发送回同一主题。 |
| migrateZookeeperOffsets |
true |
如果找不到Kafka存储的偏移量,请在Zookeeper中查找偏移量并将它们提交给Kafka。 这应该是支持从旧版本的Flume无缝Kafka客户端迁移。 迁移后,可以将其设置为false,但通常不需要这样做。 如果未找到Zookeeper偏移量,则Kafka配置kafka.consumer.auto.offset.reset定义如何处理偏移量。 查看[Kafka文档](http://kafka.apache.org/documentation.html#newconsumerconfigs)了解详细信息 |
| kafka.consumer.security.protocol |
PLAINTEXT |
如果使用某种级别的安全性写入Kafka,则设置为SASL_PLAINTEXT,SASL_SSL或SSL。 |
| Other Kafka Consumer Properties |
– |
这些属性用于配置Kafka Consumer。 可以使用Kafka支持的任何消费者财产。 唯一的要求是在前缀为“kafka.consumer”的前缀中添加属性名称。 例如:kafka.consumer.auto.offset.reset |
注意:
Kafka Source会覆盖两个Kafka使用者参数:source.com将auto.commit.enable设置为“false”,并提交每个批处理。 Kafka源至少保证一次消息检索策略。 源启动时可以存在重复项。 Kafka Source还提供了key.deserializer(org.apache.kafka.common.serialization.StringSerializer)和value.deserializer(org.apache.kafka.common.serialization.ByteArraySerializer)的默认值。 不建议修改这些参数。
官方配置示例:
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.batchSize = 5000
tier1.sources.source1.batchDurationMillis = 2000
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics = test1, test2
tier1.sources.source1.kafka.consumer.group.id = custom.g.id
Example for topic subscription by regex
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics.regex = ^topic[0-9]$
# the default kafka.consumer.group.id=flume is used
本案例kafka-source配置
agent.sources = r1
agent.sources.r1.channels=c1
agent.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.r1.batchSize = 50000
agent.sources.r1.batchDurationMillis = 2000
agent.sources.r1.kafka.bootstrap.servers = test-hadoop01:9092
agent.sources.r1.kafka.topics = topicTest
agent.sources.r1.kafka.consumer.group.id = groupTest
官网配置文件地址 : kafka-source
3.3 配置优化
主要是在放入flume-channels 的批量数据加大
更改参数:
agent.sources.r1.batchSize = 50000
agent.sources.r1.batchDurationMillis = 2000
更改解释:
即每2秒钟拉取 kafka 一批数据 批数据大小为50000 放入到flume-channels 中 。即flume该节点 flume-channels 输入端数据已放大
更改依据:
- 需要配置kafka单条数据 broker.conf 中配置
message.max.bytes
- 当前flume channel sink 组件最大消费能力如何?
4. 加大flume中channel,source,sink 各通道的单条数据量
4.1 source 发送至channels 数据量大小已配置 见 3.3
4.2 channel 配置
| Property Name |
Default |
Description |
| type |
– |
The component type name, needs to be memory |
| capacity |
100 |
通道中存储的最大事件数 (优化项) |
| transactionCapacity |
100 |
每个事务通道从源或提供给接收器的最大事件数 (优化项) |
| keep-alive |
3 |
添加或删除事件的超时(以秒为单位) |
| byteCapacityBufferPercentage |
20 |
定义byteCapacity与通道中所有事件的估计总大小之间的缓冲区百分比,以计算标头中的数据。 见下文。 |
| byteCapacity |
see description |
允许的最大总字节作为此通道中所有事件的总和。 实现只计算Eventbody,这也是提供byteCapacityBufferPercentage配置参数的原因。 默认为计算值,等于JVM可用的最大内存的80%(即命令行传递的-Xmx值的80%)。 请注意,如果在单个JVM上有多个内存通道,并且它们碰巧保持相同的物理事件(即,如果您使用来自单个源的复制通道选择器),那么这些事件大小可能会因为通道byteCapacity目的而被重复计算。 将此值设置为“0”将导致此值回退到大约200 GB的内部硬限制。 |
配置 capacity 和 transactionCapacity 值 。默认配置规则为:
$$
channels.capacity >= channels.transactionCapacity >= source.batchSize
$$
官方channels配置示例
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
本案例修改之后的channels 配置
agent.channels.c1.type = memory
agent.channels.c1.capacity=550000
agent.channels.c1.transactionCapacity=520000
5. 将flume拉取数据单机版本改成多数据拉取,通过flume-avore-sink-> flume-avore-source 进行数据多数据采取并合并
5.1 存在问题
通过上续修改会发现单机版本的flume会在多副本kafka轮询造成效率浪费
单机版本flume处理数据时会存在单机瓶颈,单机channels可能最多只能处理最大数据无法扩充
单机flume配置多个数据源不方便,不能适合后续多需求开发
5.2 修改架构
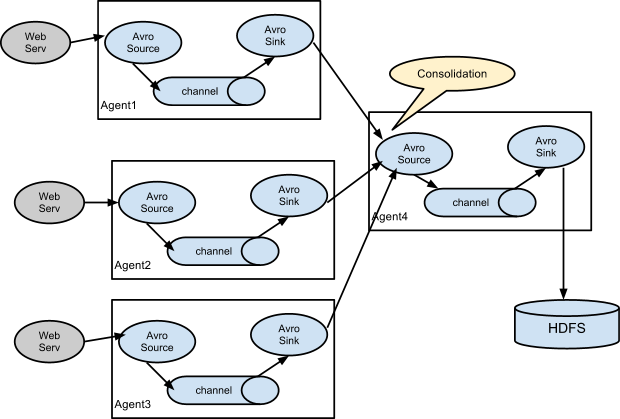
5.3采集节点配置文件
收集节点配置(3台):
agent.sources = r1
agent.channels = c1
agent.sinks = k1
agent.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.r1.batchSize = 50000
agent.sources.r1.batchDurationMillis = 2000
agent.sources.r1.kafka.bootstrap.servers = qcloud-test-hadoop03:9092
agent.sources.r1.kafka.topics = topicTest
agent.sources.r1.kafka.consumer.group.id = groupTest
agent.channels.c1.type = memory
agent.channels.c1.capacity=550000
agent.channels.c1.transactionCapacity=520000
agent.sinks.k1.type = avro
agent.sinks.k1.hostname = test-hadoop03
agent.sinks.k1.port=4545
agent.sources.r1.channels = c1
agent.sinks.k1.channel = c1
汇总节点配置(1台):
agent.sources = r1
agent.channels = memoryChannel
agent.sinks = hdfsSink
agent.sources.r1.type = avro
agent.sources.r1.bind = ip
agent.sources.r1.port = 4545
agent.sources.r1.batchSize = 100000
agent.sources.r1.batchDurationMillis = 1000
agent.channels.memoryChannel.type=memory
agent.channels.memoryChannel.keep-alive=30
agent.channels.memoryChannel.capacity=120000
agent.channels.memoryChannel.transactionCapacity=100000
agent.sinks.hdfsSink.type=hdfs
agent.sinks.hdfsSink.hdfs.path=hdfs://nameser/data/hm2/%Y-%m-%d-%H
agent.sinks.hdfsSink.hdfs.writeFormat=Text
agent.sinks.hdfsSink.hdfs.rollCount = 0
agent.sinks.hdfsSink.hdfs.rollSize = 134217728
agent.sinks.hdfsSink.hdfs.rollInterval = 60
agent.sinks.hdfsSink.hdfs.fileType=DataStream
agent.sinks.hdfsSink.hdfs.idleTimeout=65
agent.sinks.hdfsSink.hdfs.callTimeout=65000
agent.sinks.hdfsSink.hdfs.threadsPoolSize=300
agent.sinks.hdfsSink.channel = memoryChannel
agent.sources.r1.channels = memoryChannel
5.4 架构注意点
- 当前架构需要保证聚合节点机器的性能
- 当前架构新的瓶颈可能会存在存储Hdfs数据时过慢 ,导致聚合节点Channels 占用率居高不下,导致堵塞 。
- 需要关注avro 自定义source sink 的发送效率
6.flume 监控工具(http)
flume 监控工具总共有三种方式 ,我们这里为方便简单,使用内置http接口监控方式进行操作
6.1 配置
在启动脚本处设置 参数 -Dflume.monitoring.type=http -Dflume.monitoring.port=34545 即可
6.2 访问 地址 :
http://flumeIp:34545
6.3 返回结果示例 和字段解释 :
{
"CHANNEL.memoryChannel": {
"ChannelCapacity": "550000",
"ChannelFillPercentage": "0.18181818181818182",
"Type": "CHANNEL",
"ChannelSize": "1000",
"EventTakeSuccessCount": "33541400",
"EventTakeAttemptCount": "33541527",
"StartTime": "1536572886273",
"EventPutAttemptCount": "33542500",
"EventPutSuccessCount": "33542500",
"StopTime": "0"
},
"SINK.hdfsSink": {
"ConnectionCreatedCount": "649",
"ConnectionClosedCount": "648",
"Type": "SINK",
"BatchCompleteCount": "335414",
"BatchEmptyCount": "27",
"EventDrainAttemptCount": "33541500",
"StartTime": "1536572886275",
"EventDrainSuccessCount": "33541400",
"BatchUnderflowCount": "0",
"StopTime": "0",
"ConnectionFailedCount": "0"
},
"SOURCE.avroSource": {
"EventReceivedCount": "33542500",
"AppendBatchAcceptedCount": "335425",
"Type": "SOURCE",
"EventAcceptedCount": "33542500",
"AppendReceivedCount": "0",
"StartTime": "1536572886465",
"AppendAcceptedCount": "0",
"OpenConnectionCount": "3",
"AppendBatchReceivedCount": "335425",
"StopTime": "0"
}
}
参数定义:
| 字段名称 |
含义 |
备注 |
| SOURCE.OpenConnectionCount |
打开的连接数 |
|
| SOURCE.TYPE |
组件类型 |
|
| SOURCE.AppendBatchAcceptedCount |
追加到channel中的批数量 |
|
| SOURCE.AppendBatchReceivedCount |
source端刚刚追加的批数量 |
|
| SOURCE.EventAcceptedCount |
成功放入channel的event数量 |
|
| SOURCE.AppendReceivedCount |
source追加目前收到的数量 |
|
| SOURCE.StartTime(StopTIme) |
组件开始时间、结束时间 |
|
| SOURCE.EventReceivedCount |
source端成功收到的event数量 |
|
| SOURCE.AppendAcceptedCount |
source追加目前放入channel的数量 |
|
|
|
|
| CHANNEL.EventPutSuccessCount |
成功放入channel的event数量 |
|
| CHANNEL.ChannelFillPercentage |
通道使用比例 |
|
| CHANNEL.EventPutAttemptCount |
尝试放入将event放入channel的次数 |
|
| CHANNEL.ChannelSize |
目前在channel中的event数量 |
|
| CHANNEL.EventTakeSuccessCount |
从channel中成功取走的event数量 |
|
| CHANNEL.ChannelCapacity |
通道容量 |
|
| CHANNEL.EventTakeAttemptCount |
尝试从channel中取走event的次数 |
|
|
|
|
| SINK.BatchCompleteCount |
完成的批数量 |
|
| SINK.ConnectionFailedCount |
连接失败数 |
|
| SINK.EventDrainAttemptCount |
尝试提交的event数量 |
|
| SINK.ConnectionCreatedCount |
创建连接数 |
|
| SINK.Type |
组件类型 |
|
| SINK.BatchEmptyCount |
批量取空的数量 |
|
| SINK.ConnectionClosedCount |
关闭连接数量 |
|
| SINK.EventDrainSuccessCount |
成功发送event的数量 |
|
| SINK.BatchUnderflowCount |
正处于批量处理的batch数 |
|
参考地址
flume-document : http://flume.apache.org/FlumeUserGuide.html | 
 |手机版|小黑屋|Java自学者论坛
( 声明:本站文章及资料整理自互联网,用于Java自学者交流学习使用,对资料版权不负任何法律责任,若有侵权请及时联系客服屏蔽删除 )
|手机版|小黑屋|Java自学者论坛
( 声明:本站文章及资料整理自互联网,用于Java自学者交流学习使用,对资料版权不负任何法律责任,若有侵权请及时联系客服屏蔽删除 )




 发表于 2021-9-5 09:58:27
发表于 2021-9-5 09:58:27